Basic
解决什么问题
主要是缓解数据库压力
应用场景
许多Web应用都将数据保存到RDBMS(关系数据库管理系统,Relational Database Management System)中,应用服务器从中读取数据并在浏览器中显示。但随着数据量的增大、访问的集中,就会出现RDBMS的负担加重、数据库响应恶化、网站显示延迟等影响。
Memcached
memcached是高性能的分布式内存缓存服务器。一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web应用的速度、提高可扩张性。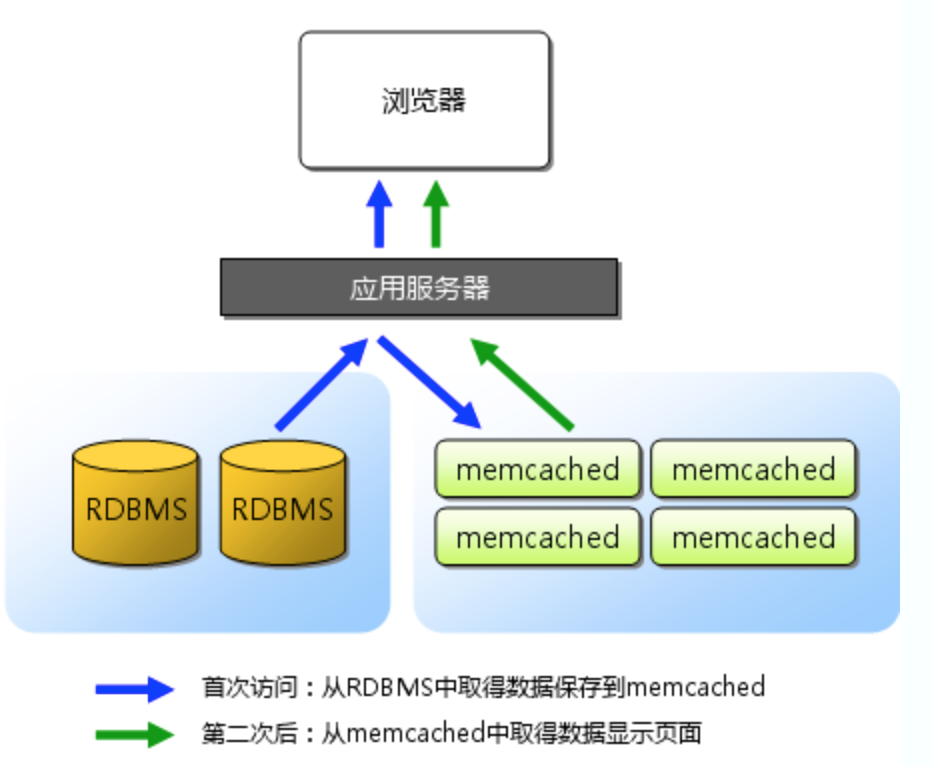
Memcached特性:
- 协议简单
- 基于libevent的事件处理
- 内置内存存储方式
- memcached不互相通信的分布式
协议简单
C/S通信不使用复杂的XML等格式,而使用简单的基于文本行的协议。
基于libevent
libevent程序库,将Linux的epoll、BSD类操作系统的kqueue等事件处理功能封装成统一的接口。及时对服务器的连接数增加,也能发挥O(1)的性能。
内置内存存储方式
为了提高性能,memcached中保存的数据都存储在memcached内置的内存存储空间中。不具有持久性。内容容量达到指定值之后,就基于LRU算法进行替换。
不互相通信的分布式
服务端没有分布式功能。各个memcached不会互相通信以共享信息。怎么进行分布式完全取决于Client端的实现。
安装
多个平台,参考官方手册。
使用
客户端api: https://code.google.com/p/memcached/wiki/Clients
操作数据
保存数据
my $add = $memcached->add(‘键’, ‘值’, ‘期限’);
my $replace = $memcached->replace(‘键’, ‘值’, ‘期限’)
my $set = $memcached->set(‘键’, ‘值’, ‘期限’)
获取数据
my $val = $memcached->get(‘键’);
my $val = $memcached->get_multi(‘键1’, ‘键2’, ‘键3’);
删除数据
$memcached->delete(‘键’, ‘阻塞时间’)
内存存储
Slab Allocation机制:整理内存以便重复使用
在该机制之前,内存的分配是通过对所有记录简单地进行malloc和free来进行的。malloc/free会导致内存碎片,加重操作系统内存管理器负担。
Slab Allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题。原理相当简单:将分配的内存分割成各种尺寸的块(chunk),并把尺寸相同的块分成组。
缓存记录的原理
memcached根据收到的数据的大小,选择最适合数据大小的slab。memcached中保存着slaba内空闲chunk的列表,根据该列表选择chunk,然后将数据缓存其中。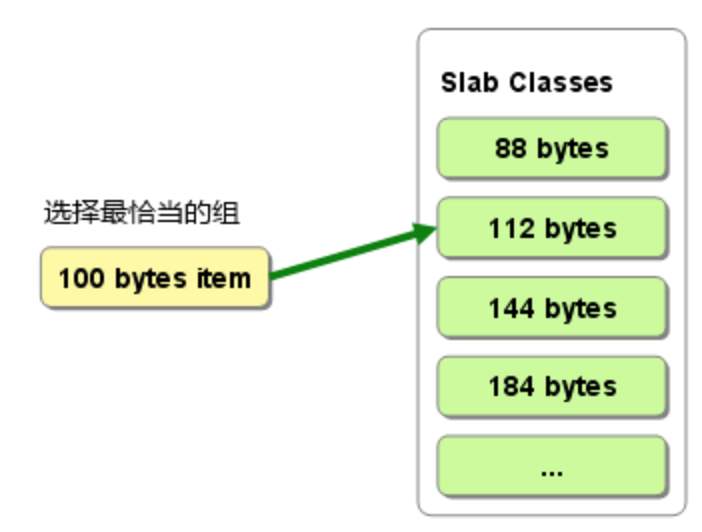
Slab的缺点
缺点也是显然的。由于分配的是特定长度的内存,因此无法有效利用分配的内存。例如将100字节的数据缓存到128字节的chunk中,剩余的128字节就浪费了。
Growth Factor调优
通过f选项,默认值为1.25。也就是组的大小为因子为1.25的等比数列。GF之前,这个因子为2,称为powers of 2策略。
删除机制
Lazy Expiration
不会主动监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过期。这种技术称为lazy expiration。
LRU
不写了。
Memcached的分布式算法
客户端实现,一致性hash算法
客户端实现
简单来说就是使用一个Hash函数,存数据的时候根据hash函数确定数据存放的服务器。当客户端取数据的时候,使用同样的hash函数就可以计算出存放数据的服务器,如果数据没有过期即可取到数据。
负载均衡:一致性哈希
我们知道使用mod的方法做负载均衡会有很多问题
一致性哈希算法简单来说,首先求出memcached服务器节点的哈希值,并将其配置到0~2^32的圆上。然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过2^32仍然找不到服务器,就会保存到第一台memcached服务器上。
相比mod 方法,一致性hash算法在插入新服务器的时候影响更小。