1.引言
Beanstalkd 是单进程的,同时也是单线程的。仔细留意一下就会发现很多高性能网络框架都是单进程的和异步的。单线程就避免了 context switch 的开销,而异步是任何高性能系统都会采用的一种架构。我们今天看一下 Beanstalkd 的框架是怎么样的?
2.select、poll、epoll
1.I/O模型
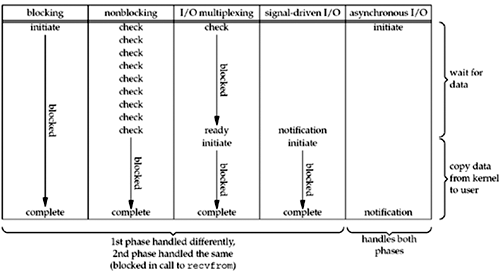
这里说的 I/O 指的都是是网络 I/O。Unix 下可用的 5 种 I/O 模型如下:
- 阻塞式 I/O
- 非阻塞式 I/O
- I/O 复用
- 信号驱动式 I/O
- 异步 I/O
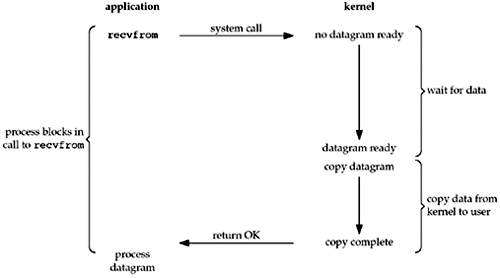
1. 阻塞式 I/O
进程调用recvfrom,系统调用直到数据报到达且被复制到应用进程的缓冲区中或者发生错误才返回。网上有很多经典的例子,比如去查看水壶的水有没有开,直到水开了或者被其他更重要的事情打断才返回。
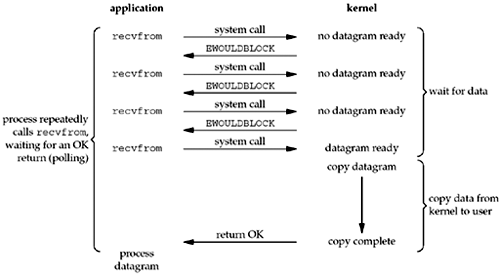
2.非阻塞式 I/O
非阻塞式I/O 与阻塞式的区别在于,询问内核数据没有准备好时候,系统调用并不会一直等待下去,而是先返回一个错误。然后隔一段时间再去查看,直到数据准备好,然后将其从内核拷贝到进程缓冲区,结束。还是以上面的查看水壶的水有没有开的例子,如果发现水没有开则返回,过一段时间再去查看。其实本质上就是轮训,这么做往往会耗费大量CPU 时间。
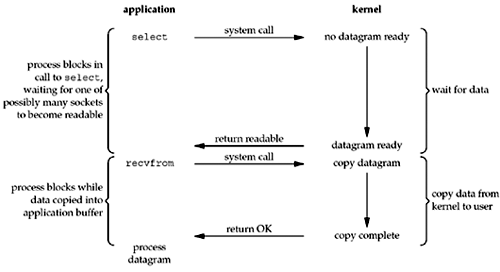
3. I/O 复用
前面阻塞式 I/O 是阻塞在一个系统调用,如果我们需要阻塞于多个系统调用,这就需要用到 IO 复用。I/O 复用借助于 select/poll 实现,select/poll 可以认为是系统调用的代理,select/poll 负责监听一组系统调用,用户进程阻塞于 select/poll,其中任何一个就绪,select/poll 都将不在阻塞。典型使用如下:
- 当需要处理多个描述符(通常是交互式输入和 socket)时,必须使用 I/O 复用。
- 处理多个 socket。
- 一个 TCP 服务器既要处理监听 socket,又要处理已连接 socket。
- …
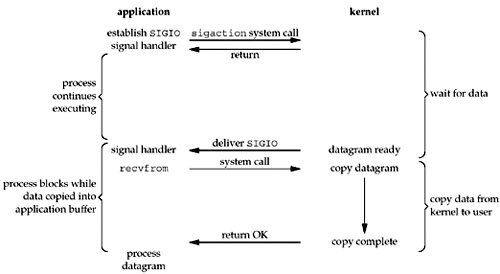
4.信号驱动式 I/O
内核在描述符就绪时发送 SIGIO 信号通知用户进程。
5.异步I/O
告知内核启动某个操作,并让内核在整个操作(包括将数据从内核复制到用户进程的缓冲区)完成后通知用户进程。这种模型有点类似信号驱动式 I/O,区别在于:信号驱动式 I/O 由内核通知何时可以启动一个 I/O 操作,而异步 I/O 模型是由内核通知我们 I/O 操作何时完成。
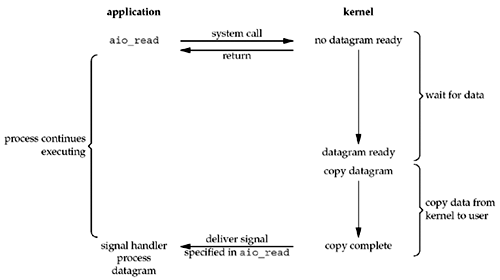
闲扯一句,非阻塞并不等同于异步。根据 POSIX 对同步 I/O 和 异步 I/O 的定义:
- A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes.
- An asynchronous I/O operation does not cause the requesting process to be blocked.
我们将上述五种 I/O 模型汇总如下,发现前四种 I/O 模型都是同步 I/O。
2. select
select 以及下面要说的 poll 和 epoll 都是 I/O 复用的系统调用API。简单介绍一下。select 函数容许进程指示内核等待多个事件中的任何一个发生,并只在有一个或多个事件发生或经历一段指定的时间才唤醒它。函数定义如下:
1 |
|
参数简单介绍一下:
- maxfdp1: 指定待测试的描述符的个数,值是待测试的最大描述符加1
- readset, writeset, exceptset 指定我们要让内核测试读、写和异常条件的描述符
- timeout: 告知内核等待所指定描述符中的任何一个就绪可花多长事件。
- 空指针:永远等待,仅有一个描述符准备好 I/O 时才返回
- 某个值:在有一个描述符准备好 I/O 时返回,但是不超过 timeout 中定义的时间。
- 0: 这种情况,根本不等待,检查描述符后立即返回,也就是轮询。
select 返回是就绪的描述符个数,但是并不会返回具体哪个/哪几个描述符就绪了,所有在用户态还需要我们自己去手动遍历文件描述符。而且我们每次调用 select 的时候都需要将所有的文件描述符从用户态拷贝到内核态(比如我的文件描述符是5),那么我需要传递的就是6个文件描述符{0,1,2,3,4,5},6个文件描述符都会被检测(内核中通过轮询传入的文件描述符来检测状态)。
select 确实解决了一些问题,但是本身也是有问题的,比如 select 支持最大描述符数目是 1024,按照常理,单个线程 1024 个描述符是够用了,但是对于高性能服务器,这是远远不够的。如果要修改这个值只能修改内核文件然后重新编译内核。
3. poll
poll 和 select 函数类似,接口定义有所区别。
1 |
|
poll 不再为每个状态(可读、可写和异常状态)构造一个描述符集,而是构造一个 pollfd 结构数组,每个数组元素指定一个描述符编号以及对其所关心的状态,也就是参数 fdarray,fdarray 数组中元素个数由 nfds 说明。
timeout 与 select 中的也不再一样,是一个 int 类型。
- timeout == -1:永远等待。当所指定的描述符中一个准备好,或捕捉到一个信号时返回。
- timeout == 0: 不等待,也就是轮询。
- timeout > 0:等待 timeout 毫秒。
poll 的第一个参数解决了 select 的最大描述符个数的限制,但是由于本质上还是和 select 一样,描述符也需要在用户态和内核态之间拷贝,内核中还是需要轮询所有的描述符,在监控的描述符数量过大,程序的性能也会受到影响。
4.epoll
前面说到 select/poll 在内核实现上都采用轮询的方式,导致性能存在瓶颈,所以就有了 epoll。epoll 是将 select/poll 的时间复杂度从 O(n) 降到了 O(1)。我们不需要传递庞大的文件描述符,而是只注册我们感兴趣的文件描述符。我们来看一下 epoll 简单用法。
epoll 使用主要包括三个函数:
- epoll_create():从内核申请一个 实例
- epoll_ctl():注册我们感兴趣的事件
- epoll_wait():等待我们感兴趣的事件发生。
关于 select/poll/epoll 的更详细的使用以及内核实现之后放到新的文章中讲吧,毕竟这篇文章主要还是来讲 beanstalkd 的。
3.beanstalkd 主流程
首先找到 main 函数,在 main.c 文件中。
1 | int |
其中 setlinebuf 用来设置文件流以换行为依据的无缓冲IO。optparse 解析命令行参数。make_server_socket 是新建一个 socket,prot_init 是做一些初始化的操作,比如,tubes 初始化。if (srv.wal.use) 里面是 job 持久化相关的,我们先不看了。最主要的在下面的 srvserve 函数。其实就是 server 的主线程。
1 | void |
其实 beanstalkd 的主流程也是使用的异步非阻塞,通过 epoll/kqueue 来实现,不过代码中又封装了一层。可以看一下这三个函数:sockinit(), sockwant(), socknext()。darwin.c 文件中是对 kqueue 的封装,linux.c 文件中是对 epoll 的封装。我们看一下 epoll 的封装。
1 | int |
可以看到这三个函数是对 epoll_create,epoll_ctl,epoll_wait 的封装。这是使用 epoll 时最基本的三个函数,这里就不再赘述。回到 srvserve 函数,for 循环里就是监听 socket 事件。
这里提个问题:就是beanstalkd 本身是有定时功能的,那么怎么通过一个主线程来实现定时和 socket 监听呢?答案就是通过 epoll_wait 的 timeout 来实现定时功能。通过 epoll_wait 来实现定时器有一个弊端,因为 epoll_wait 的 timeout 的时间精度只到毫秒,也就是意味着 beanstalkd 的时间精度也只到毫秒。
好了,让我们回到主题。通过 epoll_wait 的 timeout 来实现定时功能,也就是说 timeout 是下一个 job 到期的时间。代码里面对于的就是 prottick 函数,我们来简单看一下。
1 | int64 |
首先看到 prottick 返回的 period 是由 delay_q_peek() 返回的 job 间接生成的。我下面把 delay_q_peek() 的代码也贴出来了。一目了然。delay_q_peek() 是筛选出最快到期的 job。这里有一点值得一说的就是筛选 job 的时候,beanstalkd 采用的是遍历所有的 tube 的方法,这也就意味这如果 beanstalkd 的 tube 特别多的话,这里可能是个性能瓶颈。
上面还涉及到一些函数,像 process_queue(),heapremove(),都是对 job 的队列进行操作的,这里就不细说了。
4.参考
- 《Unix 网络编程》
- 《Unix 环境高级编程》