简而言之,mesos 是一个在多种计算框架之间协调集群资源的平台。通过 mesos,我们可以提高集群的资源利用率。mesos 的调度机制叫 resource offer,是一种 two-level 调度策略:1. mesos 决定分配给 framework 多少资源;2. framework 决定是否接受以及用来运行哪些 task。
1. 引言
随着计算框架越来越多,如果每个计算框架分配一个集群会导致某些集群的资源得不到充分利用。所以,多个计算框架共享集群资源显得非常有必要,mesos 应运而生。
设计 mesos 的一个核心问题是如何设计一个可以支持众多 framework(包括现存和未来的)的高扩展和高性能的系统。主要原因如下:
- 每个 framework 都会有自己特有的调度需求
- 调度系统要能够支持数以千计的节点以及数百万的 task
- 高可用和高容错。
上诉问题的一种解决方案是设计一个中心话的调度器,通过收集 framework 对资源的需求,集群的可用资源,以及各种策略,然后为所有的 task 做全局调度。这种方式看上去可能是全局最优的,但是有下面几个问题:
- 复杂度。scheduler 需要提供足够表现力的 API 去支持多种 framework。
- Framework 及其调度策略一直在变化。
- 对于已经有了成熟调度策略的框架,将他们的调度算法转移到全局的调度器代价非常大。
另一个解决方案是将控制权交给框架本身,这个设计抽象叫 resource offer。resource offer 将许多资源打包提供给框架,然后框架决定要不要接受这些资源以及分配哪些 task 运行。Resource offer 模型足够简单,实现起来也比较高效,这使得 mesos 具有高度的扩展性和健壮性。除此之外,这样设计还有其他好处:
- 可以使用多个版本的框架。
- 接入新框架简单。
2. Architecture
2.1 Design Philosophy
mesos 的初衷是让多种框架高效地共享集群资源。因为各种框架本身的高度不统一,mesos 最重要的设计思想是定义最小化接口助力框架之间资源共享和将 task 的调度赋权给框架本身。控制权下沉到框架有两个好处:1.每个框架可以根据自己的需要实现自己的调度算法;2.这使得 mesos 本身足够简单。
尽管 mesos 提供了 low-level 的接口,我们还是需要能在 higher-level 实现一些公共功能,比如错误处理。
2.2 Overview
mesos 是 master/slave 架构,架构图如下图。
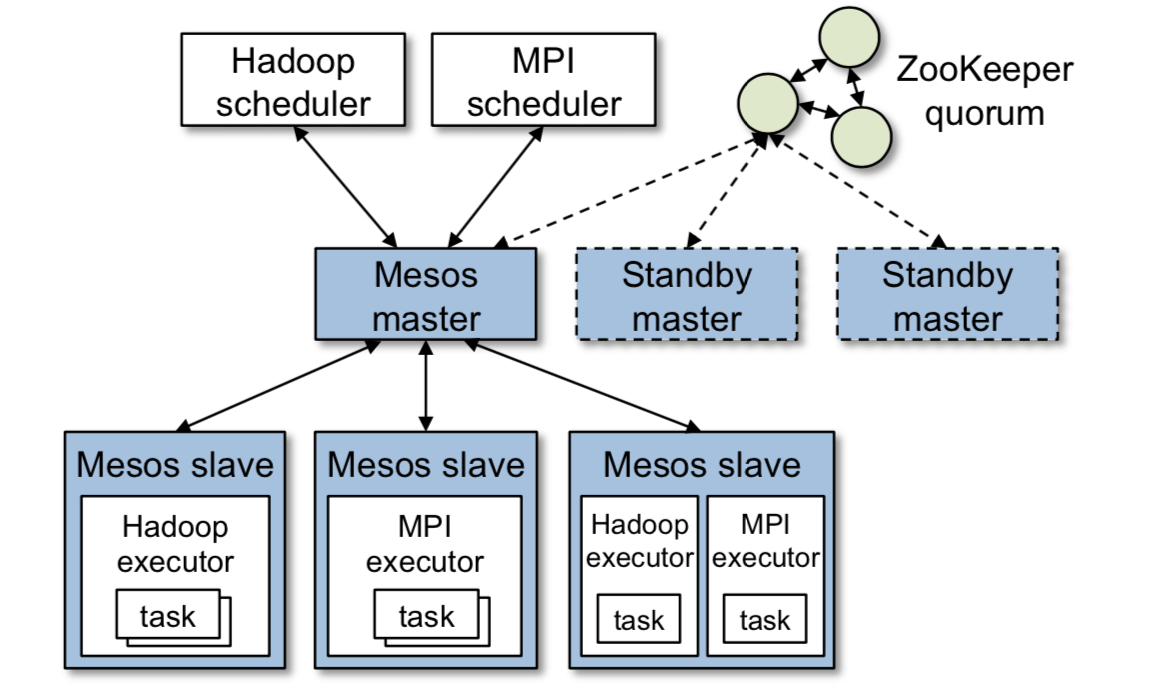
master 通过 resource offer 实现了框架之间细粒度的资源共享。resource offer 是 slave 节点上的空闲资源的 list。master 根据资源调度策略决定给每个框架分配多少资源。为了支持各种框架的资源分配策略,mesos 可以以可插拔的方式让用户自定义自己的策略。
运行在 mesos 之上的框架包括两个组件:scheduler,注册到 master 上用来接收资源;executor,负责运行 task。master 决定给 framework 分配多少资源,然后 framework 的 scheduler 选择使用与否,如果选择接受,则返回给 mesos 将要运行的 task 的描述信息。
下图是一个资源分配的例子。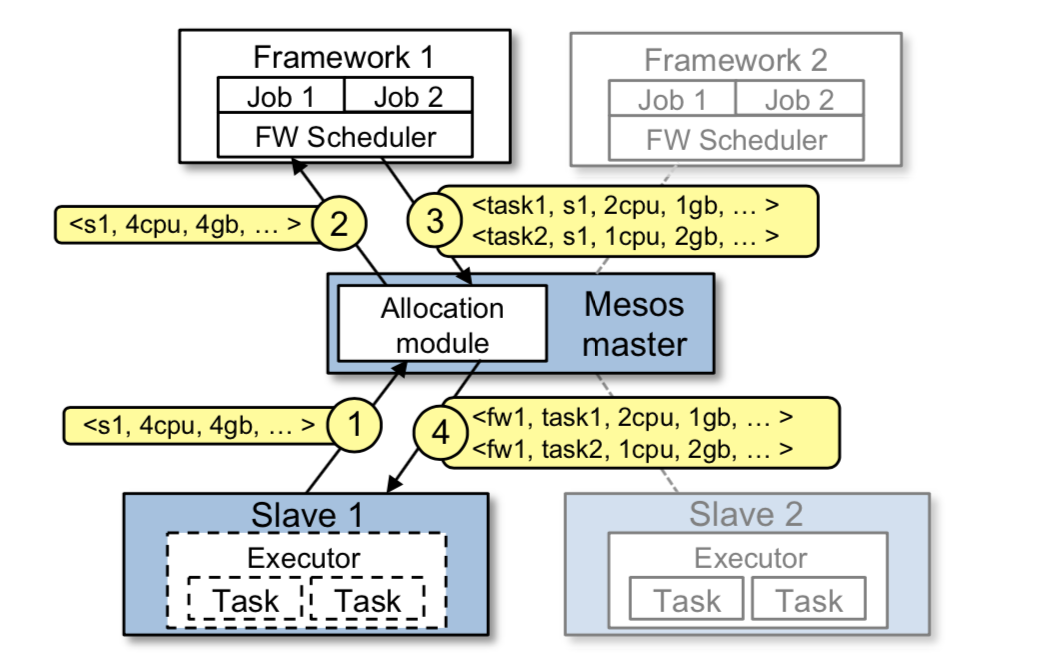
简单描述其过程如下:
- slave 1 告诉 master 自己的空闲资源情况:4 CPU 和 4 GB 内存。master 调用资源分配模块得出应该给 framework 1 分配所有空闲的资源。
- master 向 framework 1 发送 resource offer (4CPU,4GB RAM)
- frameworker 1 接受 offer,回复要运行的 task 信息:task 1 <2 CPUs, 1GB RAM> 和 task 2 <2 CPUs, 2GB RAM>
- master 将第 3 步得到的 task 下发给 slave 节点。给 framework 的 executor 分配合适的资源,然后由 executor 运行 task
为了保持 mesos 和 framework 之间的解耦,mesos 不要求 framework 对资源要求做限制。取而代之的是,mesos 给 framework 发送 resource offer,由 framework 自己决定要不要接受。这样每个 framework 就可以自定义自己资源限制条件了。这种设计的一个潜在的问题是效率问题:framework 可能要等很长时间才能得到满足自己需求的资源,mesos 要将一个 resource offer 发送给很多 framework 才会被其中一个接收。
对于这种情况,mesos 的解决方案是 framework 设置 filter 做一个初步的过滤。
2.3 Resource Allocation
mesos 的资源分配模块是可插拔的,这样开发者可以做一些定制化策略。目前,mesos 本身提供两种分配策略:1. 基于 max-min fairness 的泛化算法(其实就是 DRF);2. 基于优先级的严格策略,类似 Hadoop 和 Dryad 使用的策略。
正常情况下,大多数 task 运行时间都很短,当 task 完成的时候才会重新分配资源。这也就意味着 framework 可以快速获得资源。比如,如果一个 framework 的集群使用份额是 10%,它需要等待 task 的平均时长的 10% 左右时间去获得资源。然而如果一个集群运行很多周期很长的 task 或者有问题的 job 导致资源一直得不到释放,这时候 mesos 可以通过 kill 来解决(graceful kill)。这里 kill 哪个 task 将由模块具体实现,不细说了。
2.4 Isolation
隔离使用的操作系统容器技术里面的隔离机制,cgroup 等,不再细说。
2.5 Making Resource Offers Scalable and Robust
因为 mesos 中的调度是一个分布式程序,需要考虑一下性能和健壮性。mesos 主要通过以下三点来保证。
- 对于某些总是拒绝 master 的 resource offer 的 framework,master 将先执行 framework 的 filter。filter 是一个布尔函数,能够快速得到结果。
- 激励 framework 更快响应 offer。
- 如果一个 framework 在足够长的时间里面没有对 offer 做出响应,mesos 将收回 offer 并将 offer 提供给其他的 framework。
2.6 Fault Tolerance
由于所有的 framework 都依赖 mesos master,所有提高 master 的容错很有必要。为了达到这个目的,master 被设计成 soft state,也就是说一个新的 master 可以通过 slave 和 framework 重新构建出 master 的状态。补充一下,master 的状态包括 active slaves, active frameworks 和 running tasks。如前面的架构所示,多个 master 的集群通过 ZooKeeper 来完成选主。
除了 master 容错,mesos 还将节点失败和 executor crash 上报给 framework 的 scheduler,以便 framework 做一下容错处理。
最后,对于 scheduler 的容错处理,mesos 容许 framework 注册多个 scheduler,多个 scheduler 之间的状态管理由 framework 自己完成。
3. Implementation
mesos 最开始由大概 10000 行 C++ 代码编写而成,可以运行在 Linux,Solaris 和 OS X,支持多种由 C++,Java,Python 实现的 framework。
为了减小复杂度,mesos 使用了一个 C++ 库 libprocess。libprocess 提供基于 actor 的编程模型。同时 mesos 使用 ZooKeeper 来做 leader 选举。隔离技术使用的 Linux 容器技术。
剩下篇幅介绍了如何支持以下三个 framework:Hadoop,Torque 和 MPI。这里的 Hadoop 调度使用还是 MapReduce 1.0,我们当然就不再介绍了。
4. 其他
其他关于 mesos 的一些评估,因为论文中的评估太久远了,这里就不细说了,具体可以参考 mesos 的官网。