过去一段时间很长的一段时间内都在写用 spark streaming 来做一些规则引擎的工作,工作第一阶段暂时告一段落,这里简单做一下总结。
0. spark streaming 是什么
streaming 不言而喻,也就是实时流式处理。严格来说 spark streaming 并不能算实时流式处理,它的工作原理是一种 micro batch 的方式,也就是说它会将很多 record 放在一起组成一个 batch 然后当成一个批处理作业进行处理。这也是它和 storm, flink 最本质的区别。
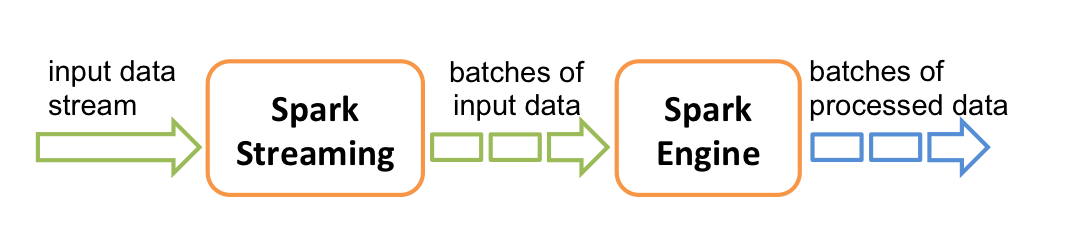
micro batch 的好处在于吞吐更大,延迟取决于 batch interval,如果对于实时要求不是特别的高,同时也在使用 Spark 的其他功能,Spark Streaming 往往是一个不错的选择。
1. 数据模型
DStream,也就是 discretized stream,是 Spark Streaming 提供了一种 high level 的抽象,用来表示数据流,数据一般从 Receiver(比如 Kafka, Flume等) 中获取。在内部,DStream 由一系列的 RDD 组成。RDD 是 Spark 中定义的一种数据模型,全称是 Resilent Distributed Dataset,可以简单理解为一个不可变的分布式数据集合。这些写代码的时候就可以像下面这么写:
1 | DStream.foreachRDD(rdd => {rdd 处理}) |
大括号里面的 rdd 处理和普通的 Spark 程序处理基本没有区别,主要是通过一系列的 RDD 算子构造一个 DAG。这样其实就是把 Spark Streaming 转化成了一个个 Spark 作业了。
2. Streaming Context
StreamingContext 是 Spark Streaming 程序的入口,我们一般先初始化一个 SparkConf,然后 StreamingContext 初始化的时候使用这个 SparkConf,代码如下。
1 | val conf = new SparkConf().setMaster("local[2]").setAppName("Example App") |
local[2] 表示 local 模式使用 2 个线程运行 Spark Streaming 程序,注意如果是 local 模式一定要多初始化几个线程,因为 receiver 会独占一个线程,也就是 n > receiver_num。
3. Receiver
通过上面初始化的 ssc 就可以构造 DStream 了,比如 Spark 自带的 WordCount 示例代码。
1 | // tcp as receiver |
Spark Streaming 支持的 receiver 有 Kafka, Kinesis, Flume, Tcp socket,已经通过其他算子产生的流。除此之外还支持 custom Receiver,customReceiver 继承类 org.apache.spark.streaming.receiver.Receiver ,然后实现特定的方法即可。示例代码如下。
1 | // Create an input stream with the custom receiver on target ip:port and count the |
4. DStream Join
如果在一个 Spark Streaming 程序里面要处理多个 DStream 怎么办呢?DStream Join
1 | val stream1: DStream[String, String] = ... |
5. 算子介绍
Spark RDD 支持的算子基本都可以应用到 DStream 上。
Transformation
- map(func):DStream 每个 record 通过 func 产生一条新的记录,并组成一个新的 DStream
- flatMap(func): 类似 map,区别在于每个 record 可以产生多个 record
- filter(func): 返回 func(record) = true 的 record 组成的新的 DStream
- repartition(numPartition): 调整 DStream 的 partition 个数
- union(otherStream): 组合多个 DStream
- count(): 返回 DStream 的个数
- reduce(func): 通过 func 处理 Dstream 里的所有元素最后返回一个值
- countByValue(): 返回 key 的频率统计
- reduceByKey(func, [numTasks]): 对于 pair 数据 (K,V),对相同的 K 进行聚合执行操作 func(V1, V2)
- join(otherStream, [numTasks])
- cogroup(otherStream, [numTasks])
- transform(func): 对 DStream 里面的每个 RDD 都执行一下 func 操作,返回一个新的 DStrem
- updateStateByKey(func): 通过联合多个 DStream,保存 key 的状态信息。
Output Operation
- print(): 返回 DStream 里面每个 batch 的前十个元素
- saveAsTextFiles(prefix, [suffix]): 保存为 Text File
- saveAsObjectFiles(prefix, [suffix]): 保存为 SequenceFiles
- saveAsHadoopFiles(prefix, [suffix]): 保存为 Hadoop 文件
- foreachRDD(func): 对于 DStream 中的每个 RDD 执行 func 操作,func 操作执行在 Driver 上。
6. 总结
更详细的介绍我后面再展开说。